at work i’m using mysql replication quite extensively. first it was a straightforward one-way replication that has been rock-solid for us since 2009. in 2012, for another type of data, we’ve started using master-master setup. initially the servers were in different European countries, eventually the secondary site was moved to North America while primary one remained in Europe. i’ve described the setup in this post.
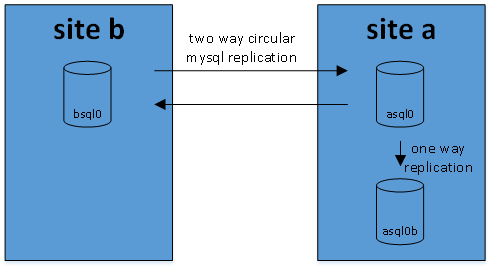
clients periodically select preferred site based on the lowest response time. their request generate simple read/write queries; updates get asynchronously replicated between both sites. if you google about similar setup you’ll find a lot of warnings – this architecture might lead to inconsistency when contradicting updates arrive nearly at the same time to both sites. in our case it’s highly unlikely. also, we have extensive monitoring and alerting based on pt-table-checksum and a simple automated conflict resolution script. it has worked very well for us and gave multi-year 100% service availability also in a few events of network outages affecting either of the datacenters.
in 2017 we’ve expanded this setup and added a third site – in South East Asia. it was done to bring the client-facing application servers closer to our new users in that region and decrease the UI latency. users like responsive interfaces. as with the original setup from 2012 i was reluctant at first – i expected to see plenty of inconsistencies. it did not happen – so far it worked flawlessly. here’s the new architecture:
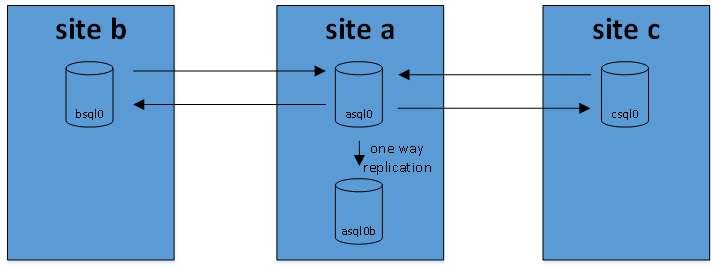
in this setup asql0 is using multi-source replication – a mechanism that is available since mysql 5.7. it fetches and replies binlogs from both bsql0 and csql0; thanks to the log-slave-updates directive it also acts as replication master for asql0b that collects all updates done to asql0, bsql0, csql0.
configuration needed for this setup:
asql0 – the ‘central’ node – my.cnf:
server-id = 10 # must be unique across all servers connected in the replication graph log_bin = /var/log/mysql/mysql-bin.log auto_increment_increment=3 # thanks to this and one below we avoid conflicting auto-increment ids when inserts occur around the same time on different replication masters auto_increment_offset=3 # this one must be different for each master, in my case it's 3 for asql0, 4 for bsql0, 5 for csql0 log-slave-updates # allows updates done on bsql0 to reach csql0 and asql0b bind-address=* master-info-repository=TABLE # more durable way of storing the replication position relay-log-info-repository=TABLE binlog_format=STATEMENT # ROW would be nice but i don't want to give up on the pt-table-checksum which requires statement based replication
bsql0 – my.cnf:
server-id = 11 log_bin = /var/log/mysql/mysql-bin.log auto_increment_increment=3 auto_increment_offset=4 bind-address=* binlog_format=STATEMENT
csql0 – my.cnf:
server-id = 12 log_bin = /var/log/mysql/mysql-bin.log auto_increment_increment=3 auto_increment_offset=5 bind-address=* binlog_format=STATEMENT
to connect bsql0, csql0, asql0b to the master i had to restore on them master’s backup that included binlog position and issue on then:
find bsql0 master position – on bsql0:
show master status;
let asql0 connect to bsql0:
change master to master_host='bsql0',master_user='repl',master_password='repl',master_log_file='mysql-bin.000003',master_log_pos=154 for channel 'btoa';
similarly for csql0 – find out its current master position and let asql0 connect o it:
change master to master_host='csql0',master_user='repl',master_password='repl',master_log_file='mysql-bin.000003',master_log_pos=154 for channel 'ctoa';
then let bsql0 to replicate from asql0; bing log position taken from asql0 backup that was earlier restored on bsql0 – on bsql0:
change master to master_host='asql0',master_user='repl',master_password='repl',master_log_file='mysql-bin.000003',master_log_pos=154 ;
and on csql0 – similarly:
change master to master_host='asql0',master_user='repl',master_password='repl',master_log_file='mysql-bin.000003',master_log_pos=154 ;
if you’ve reached that far you’ve probably already realized that asql0 is a single point of failure. during the outage of asql0 transactions from bsql0 will not reach csql0 and vice-versa. we can tolerate it for a few minutes but not hours. our solution:
- sql table ‘repl_test’ with two columns – hostname and timestamp. three rows in it – one for asql0, another bsql0, last – csql0
- each of the master servers updates every 3 seconds entry for its hostname with the current timestamp; each of the masters keeps local clock in sync using NTP
- a periodically run consistency script calculates difference between max and min timestamps; if it’s below a tolerance threshold – it sends ‘all ok’ message to the site c
- if site c does not receive ‘all ok’ message for more than 2 minutes – it shuts down the client access to it; thanks to in-built failover clients switch to site a or site b
this simple mechanism allows us to withstand failure of site a – in the worst case all of the users will switch to the site b.
the real setup is more complex. in addition to above there are:
- multiple database shards, each replicated in a similar fashion
- more read-only slaves in different locations, used for backups, snapshots
- cron jobs frequently fetching binlogs from all master servers to central backup server
- vpns / ssl tunnels between the sites protecting the replication data flowing between the sites