in branch offices i tend to install two identical pcs running linux and working in active – hot-spare setup. things evolved over time – one location has both routers running under vmware esxi on two different hosts, another – hardware raid, other – desktop-class pcs with single hard drives. hardware raids are good as long as there’s plenty of similar devices around and swapping the raid controller in case it dies is an option. mdadm [software] raid1 might be a reasonable solution for me during the next round of hardware upgrades. below some notes from testing it under vmware and on a physical machine.
i’m running the setup using release candidate of debian wheezy with two separate hard drives. in the installer’s boot menu i select Advanced options > Expert install, after choice of language, keyboard layout, network parameters and login credentials and disk detection phase i reach the interesting part – Partition disks > Manual.
there i repeat all the steps for first and second drive – sda and sdb.
- create gpt partition table
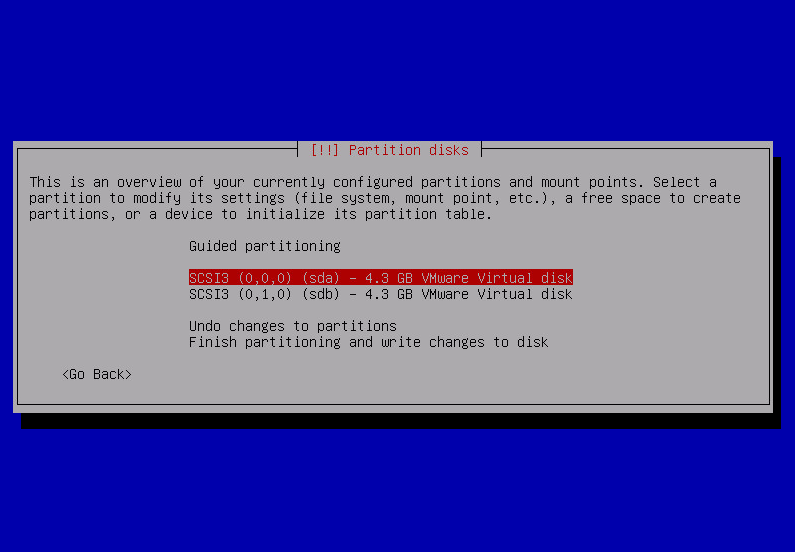
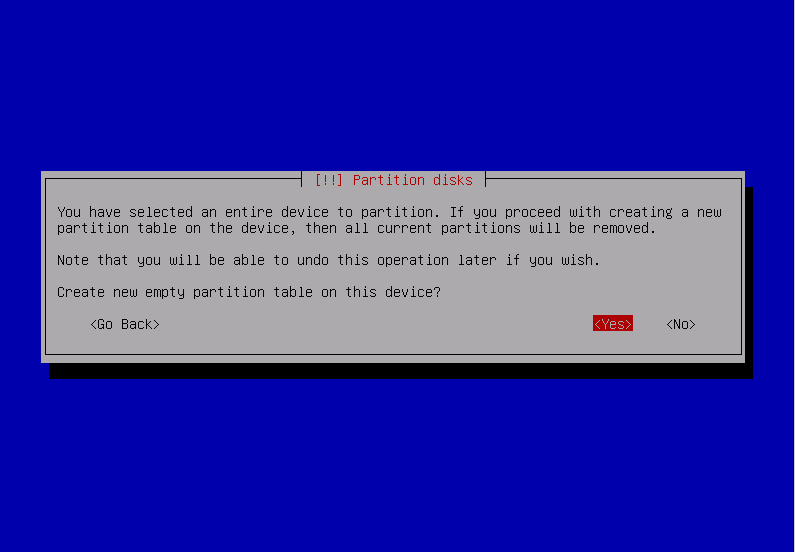
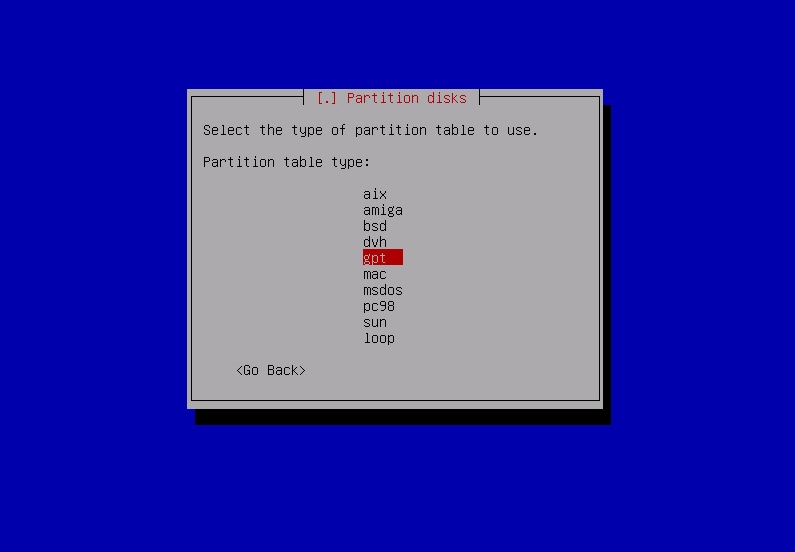
- create partitions:
- 1MB partitioni marked Use as: Reserved BIOS boot area/do not use
- 2018 addition: 100MB EFI System Partition
- as many partitions as needed for the OS. all of them marked Use as: physical volume for RAID
final result of the partitioning physical drives:
2018 version:
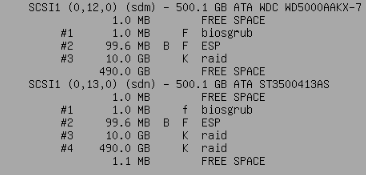
earlier version:
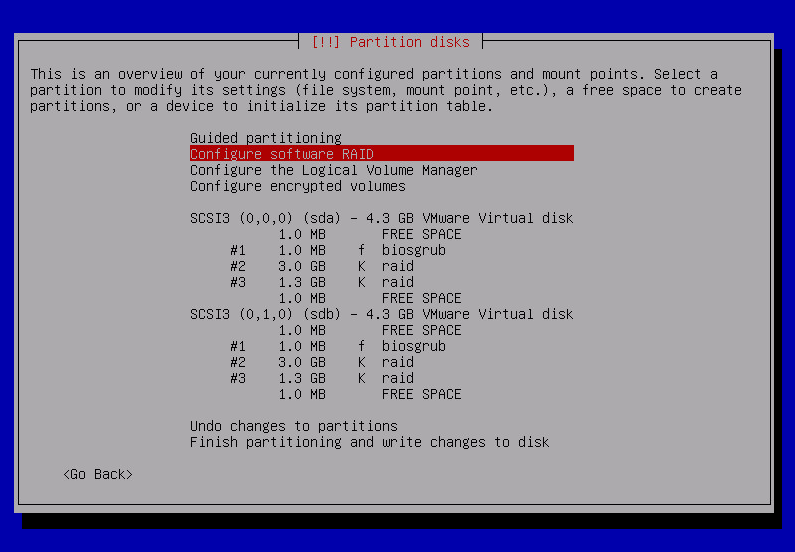
Using Configure software RAID i’m creating raid 1 devices on pairs of partitions earlier marked as physical volume for RAID.
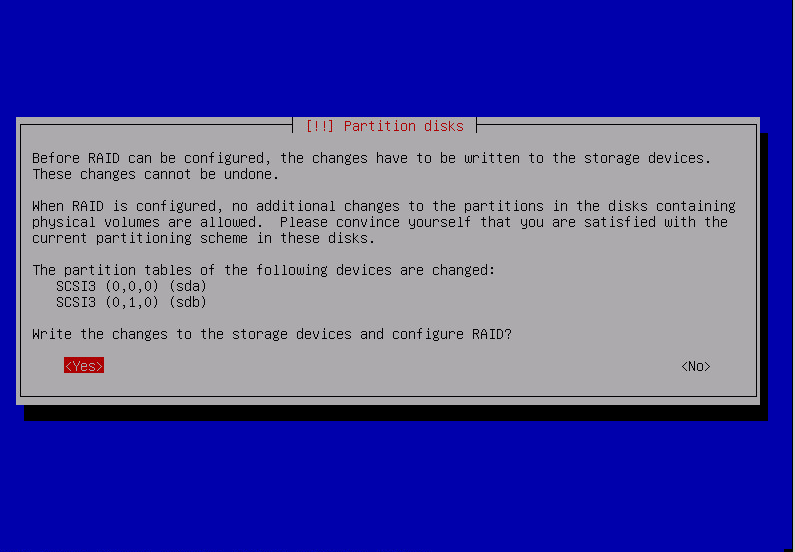
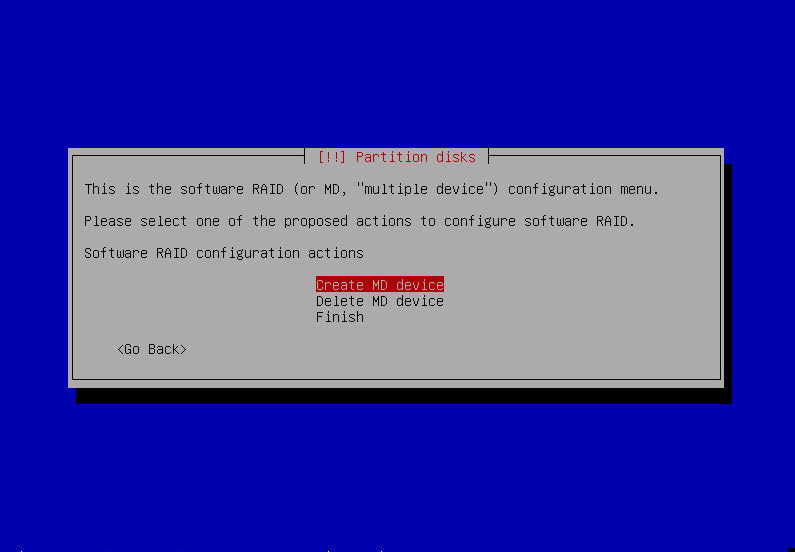
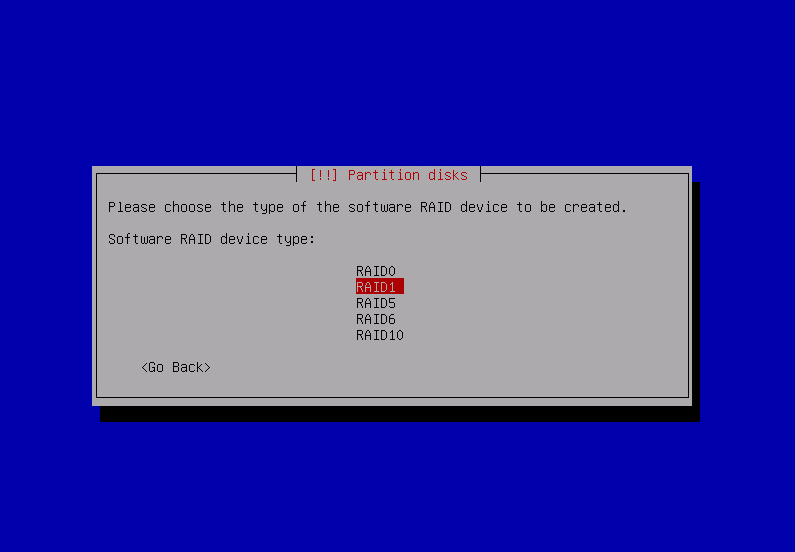
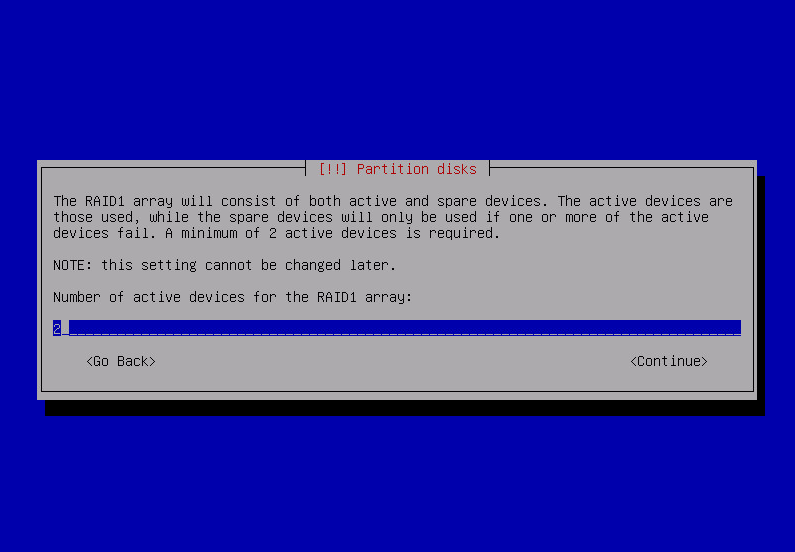
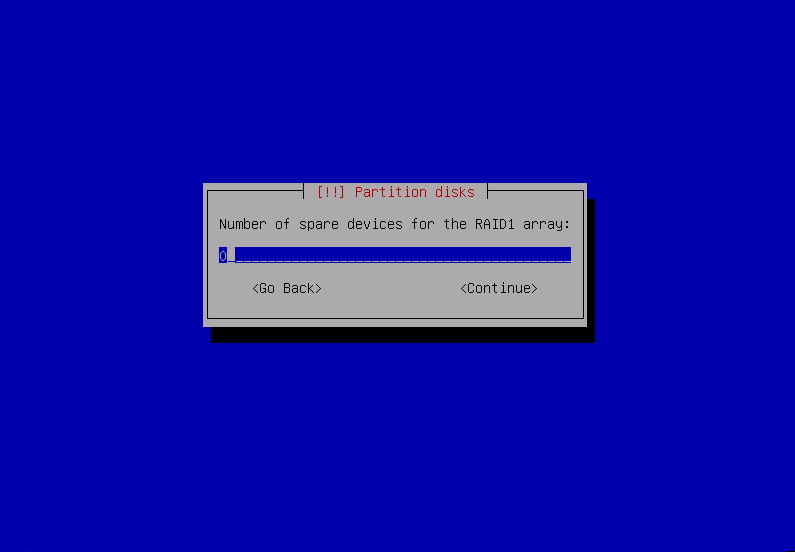
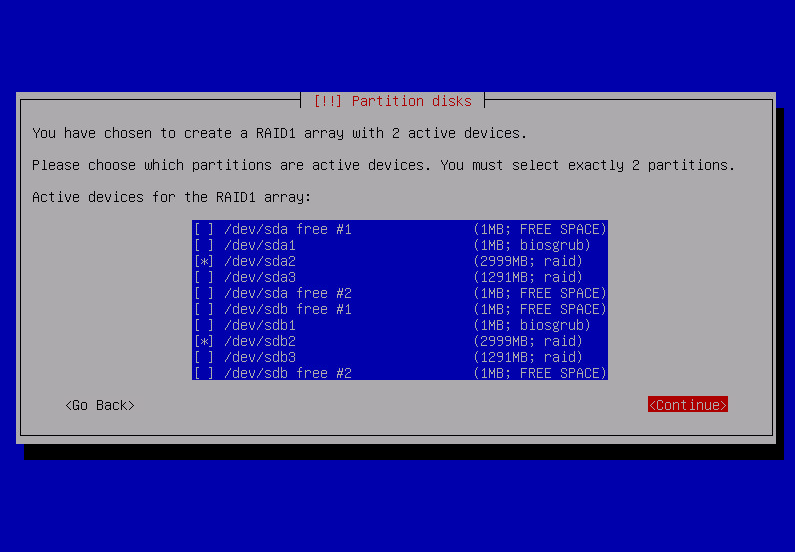
after repeating that for all raid partitions:
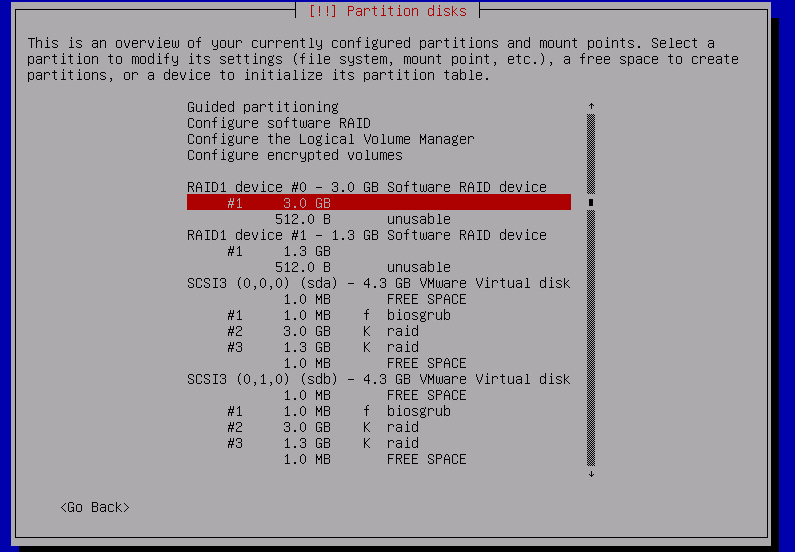
now file systems and mount points can be defined for newly created mdX devices spanning across both drives. in my case it’ll be just root and swap:
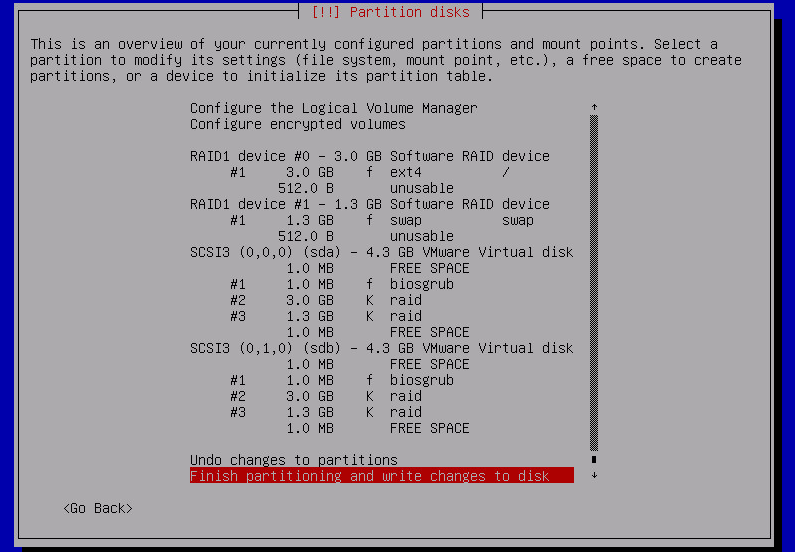
after Finish partitioning and write changes to disk there’ll be set of usual questions about packages and mirrors. when asked where to place the GRUB boot-loader i leave the default option – Install the GRUB boot loader to the master boot record: Yes:
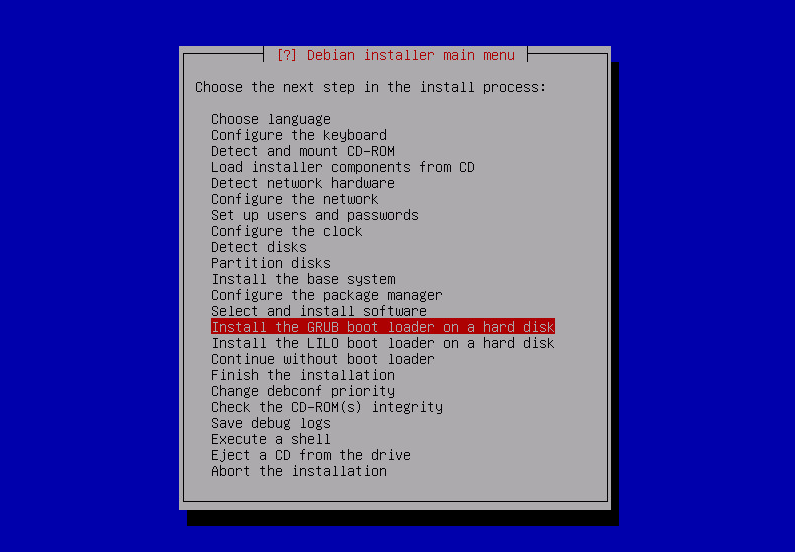
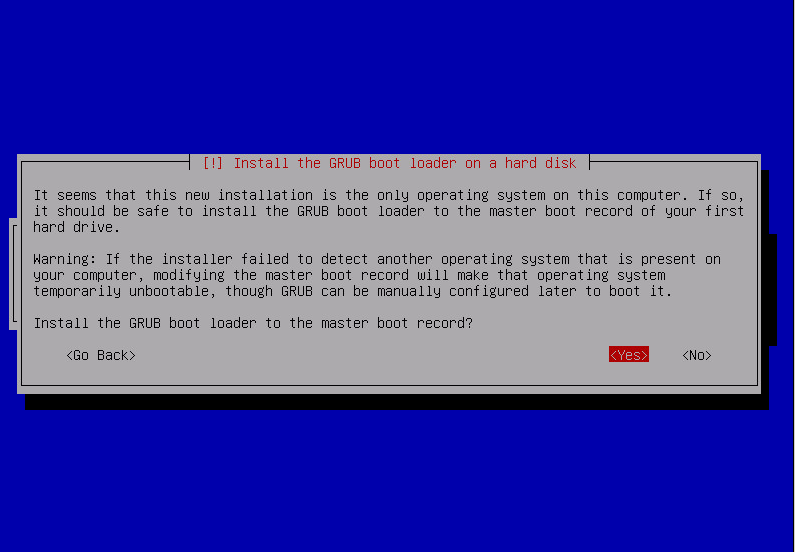
after the reboot / and swap [in my case] already is mounted from the RAID1 spanning both physical drives but i have to install manually grub on the 2nd drive so the system can boot even if the first disk is physically removed:
root@debian:~# grub-install /dev/sdb Installation finished. No error reported.
and voilà – the system will boot up even if the first drive gets physically removed.
status of all raids can be checked by:
root@debian:~# cat /proc/mdstat
Personalities : [raid1]
md1 : active (auto-read-only) raid1 sda3[0] sdb3[1]
1260480 blocks super 1.2 [2/2] [UU]
md0 : active raid1 sdb2[1]
2927552 blocks super 1.2 [2/1] [_U]
unused devices: <none>
status of single mdX device:
root@debian:~# mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sun Apr 28 12:03:26 2013
Raid Level : raid1
Array Size : 2927552 (2.79 GiB 3.00 GB)
Used Dev Size : 2927552 (2.79 GiB 3.00 GB)
Raid Devices : 2
Total Devices : 1
Persistence : Superblock is persistent
Update Time : Sun Apr 28 12:34:09 2013
State : clean, degraded
Active Devices : 1
Working Devices : 1
Failed Devices : 0
Spare Devices : 0
Name : debian:0 (local to host debian)
UUID : 9ebb319c:b0463e21:4d852665:f6527d33
Events : 75
Number Major Minor RaidDevice State
0 0 0 0 removed
1 8 18 1 active sync /dev/sdb2
to re-add disk removed earlier for a while:
root@debian:~# mdadm -a /dev/md0 /dev/sda2 mdadm: added /dev/sda2 root@debian:~# mdadm -a /dev/md1 /dev/sda3 mdadm: added /dev/sda3
to force a consistency check on a single mdX device:
echo check > /sys/block/md0/md/sync_action
to clone partition setup from one disk to another [for instance when new blank drive was installed replacing failed disk] i use gdisk:
#sgdisk is part of debians gdisk package. it's available for squeeze via backports #partition data from sda will be copied to sdb sgdisk -R=/dev/sdb /dev/sda
after that repeat for all mdX:
mdadm -a /dev/md0 /dev/sdb2
and after a while of syncing it’s done.
side notes:
- RAID1 is not a replacement for scheduled and monitored backups – it’ll not save any information in case of accidental delete
- BIOS of the computer has to be configured with both drives added to the ‘boot order’ so the OS can be loaded even if the first disk is gone
- disk swapping has to be done with the power off. i’ve tried to simulate hdd failure by disconnecting a running drive while the system was running – all my attempts ended with the OS crash.
- grub-install /dev/sdb should be repeated whenever there’s update of grub / kernel
- to force re-read of the partition table after modifications i used partprobe /dev/sdb;/sbin/blockdev –rereadpt /dev/sdb
following resources were helpful:
- https://raid.wiki.kernel.org/index.php/Linux_Raid
- http://kb.haeringer.org/configuring-a-raid1-with-mdadm-on-debian-squeeze/
- http://www.ducea.com/2009/03/08/mdadm-cheat-sheet/
2018 notes / debian stretch
- besides the 1MB Reserved BIOS boot area i had to add EFI System Partition on both boot disks, each having 100MB
- to make the system bootable from both drives i’ve cloned content of that partition between the disks: dd if=/dev/sdX2 of=/dev/sdY2 bs=1M, looks like this cloning does not have to be repeated too often
Awesome tutorial… I spend a quite some time around this setup before I figure out about the “Reserved BIOS boot area/do not use”
I wonder though… what If I create 3 physical raid partitions…
1 – Swap
2 – System
3 – LVM
But instead of just putting / in md1 in my case (md0 for you’re example) could I also set / /boot /var in separated partitions?
I tried this but I always get the error about not being able to install grub, and my install cd doesn’t come with grub-install I seems
it seems perfectly doable. swap actually does not have to be on the top on MD-raid, when partitioning ‘raw’ disks you can make separate swap partition on the 1st and 2nd drive. for system – [i assume it’s / including /boot?] – make md on the top of ‘raw disk partitions’. same with lvm – place it on the md raid on the top of ‘raw disk partitions’.
i have run grub-install from the console of the newly installed system – already after debian installer has finished and system was rebooted.
I was having problems with the installer, because when we create an MD-raid partman only allows to “use whole disk” I can’t redo the partition layout, so I was booting to the liveCD and using gdisk/parted I redo the md1 , create gpt scheme and a few partitions (/boot, /, /var/, /ur and /home, since I prefer to keep things apart and use different mount options like nodev, nosuid or boot as ro etc).
But only yesterday I figured out I have to re-select the “Reserved BIOS boot area” for the first 1MB partition in the sda or it will fail to install grub..
If I simple format the md1 whole disk has ext4 and place / there…. The installer works Ok!
I’m also thinking on putting swap out of the raid1/mirror, since this are SSD’s, and I have 2 other HDDs…
This setup is for a Xen server actually… The host it self won’t probably use much RAM, I will in fact limit it to probably 256MB at most… and won’t use much swap either.
Having the LVM in a different raid device is the most important part I guess.
I could also go for:
raid1:
md0 = /boot
md1 = / /var /usr /home
md2 = LVM
“i have run grub-install from the console of the newly installed system – already after debian installer has finished and system was rebooted.”
I see but that’s for sdb right? sda is already done by the installer!?
I’m more of a BSD admin, so I do have less knowledge of linux and grub!
yes – grub-installer was just for sdb – to make that the system will boot up just fine even if the drive associated with sda during the installation disappears. but running it also aginast /dev/sda as well should not cause any harm either.
in my limited tests linux did not handle well disk that was violently disconnected while things were working [ i wanted to simulate sudden drive failure ]. so i decided not to bother with mirroring swap. fact that some of the swap partitions were not available during the bootup did not stop the system from getting up cleanly.
out of curiosity – what will be your xen guests – linux vms? windows? bsd?
Actually all, FreeBSD, Linux and Windows!
I also need some recent Xen feature, which is why I’m going for Linux Dom0, or else I would be using BSD (NetBSD is great for a Xen Dom0) I have a similar setup at home with NetBSD’s RaidFrame and LVM for all guests expect FreeBSD (for that I use to raw disk, pass the block device’s to the DomU and use a ZFS mirror)
Does that 1MB Free space is intentional at the end and beginning of the partition or just made by the partitioner frontend?
Won’t the uuids like e8bda3c8-7955-4475-b359-c7c4acd138b6 cause a problem when you booting from the second disk?
Although these are might be the md0-9 devices uuids if you stop putting certain partitions into RAID (as suggested here) like swap, boot you will run into trouble, because these IDs will be completely different on the second disk.
What would you say about that?
hi!
1MB is more or less arbitrary number – at least at the beginning you need some space to make sure partition is aligned to 4kB sector size of modern disks [probably 32 or 64kB for SSDs]
regarding the UUIDs – it’ll work fine – here is a snippet from machine where i tested booting with degraded raid [with 1st disk missing and 2nd present, then with 1st present and 2nd missing]:
root@xxxrtr0:~# blkid /dev/sda1 /dev/sda1: UUID="e8a50bcf-fc70-17a6-cacf-01c0a1d2c6ba" UUID_SUB="90ffe7ac-d3e3-2c83-4daf-afdc33acc84b" LABEL="xxxrtr0:0" TYPE="linux_raid_member" root@xxxrtr0:~# blkid /dev/sdb1 /dev/sdb1: UUID="e8a50bcf-fc70-17a6-cacf-01c0a1d2c6ba" UUID_SUB="e4fd13b6-8577-8549-8154-291cf4536f67" LABEL="xxxrtr0:0" TYPE="linux_raid_member" root@xxxrtr0:~# blkid /dev/md0 /dev/md0: UUID="55a8e118-5f24-4bfd-a648-22af7bee810f" TYPE="ext4" root@xxxrtr0:~# cat /proc/mdstat Personalities : [raid1] md0 : active raid1 sda1[0] sdb1[1] 4877248 blocks super 1.2 [2/2] [UU] bitmap: 1/1 pages [4KB], 65536KB chunk .. root@xxxrtr0:~# head /etc/fstab UUID=55a8e118-5f24-4bfd-a648-22af7bee810f / ext4 errors=remount-ro 0 1 ..UUID of the md0 [rather than one of physical underlying partitions] is used ; grub also refers to 55a8e118-5f24-4bfd-a648-22af7bee810f [it ‘understands’ MD-RAID1 ]
Hello Dear Sir. Recently tried to make RAID1 on MBR partitions scheme on Debian Jessie. I have unable to boot from second drive after grub-install /dev/sdb. RAID1 inself for / swap and home is fully functional. Decided to try the same thing on GPT, same story. Did You tried to boot from second drive on most recend Debian Branches? Thanks in advance.
sadly i can reproduce it as well.
quick googling gave me this bug: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=781172
sadly i can reproduce this problem as well under a vm
we’re not the only one encountering it: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=781172 https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=784823 https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=784070
in the 2nd thread there’s a link to http://serverfault.com/questions/688207/how-to-auto-start-degraded-software-raid1-under-debian-8-0-0-on-boot which contains [rather hairy] workaround.
if you boot a system with a missing disk, in the recovery shell run mdadm –run /dev/md0; mdadm –run /dev/mdX; reboot – the system will boot up fine.
Very shame story…
Dear Sir. Did You tried latest CentOS or Red Hat? Do they have same behavior?
no – i did not try other OS’es but i’m pretty sure that this particular bug is affecting only Debian and possibly its derivatives like Ubuntu.
Did You try anything except Debian in same case?
on production servers i’m using only Debian
There is some movement on
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=784070
Thats good!
yes. thanks – i’m following as well this and related bug reports. hopefully the patch will be merged and eventually released in the stable Jessie.
Seems to be no chances for stable unfortunately. Patch for bug produced for unstable mdadm. :(
there’s some hope: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=805894
bingo!
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=809210#20 – a patched version of the mdadm package has been released as ‘jessie-proposed-updates’.
i’ve done a quick test using VM and manually downloaded and installed mdadm_3.3.2-5+deb8u1_amd64.deb from http://ftp.debian.org/debian/pool/main/m/mdadm/ – it works fine!